jeff.dallien.net
jeff @ dallien.net

Menu:

Post History:



Another level of Continuous Integration
February 25, 2009 22:18
The Continuous Deployment strategy used by IMVU discussed in this post (and this earlier one) is very interesting, but the thing that really impressed me was the seriousness with which they approach Continuous Integration.
4.4 machine hours of automated tests running in 9 minutes. Thousands of test files spread over 30-40 machines. I’ve had builds fail because the build server ran out of disk space.
Using Remember The Milk to track monthly bills
February 22, 2009 12:43
I really like using Remember The Milk to manage various todo lists and a shopping list but the most useful list I’ve created is one to track due dates of monthly bills. I started by creating a separate Bills list to keep the list uncluttered and easy to check with a quick glance. This is done through Settings, on the Lists tab.
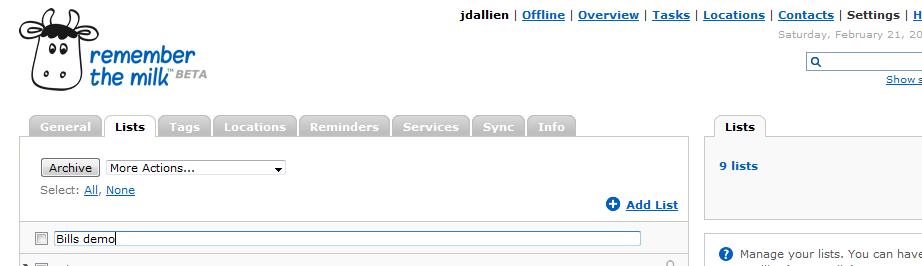
Then I started adding tasks to the list, each task being a monthly bill. I set the due date to the next time the bill is due and set the Repeat option to monthly.
Keyboard shortcuts:
- Press d to set the due date of a selected task
- Press f to set the repeat option
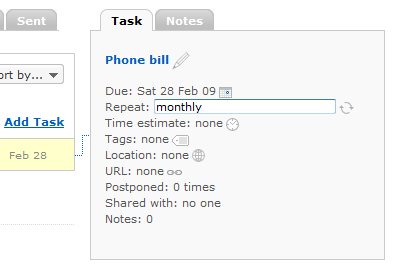
After the bills have been added, the top of the list always shows which bills are due next, since the list is ordered by task due date. When I pay a bill, I just mark the task as completed.
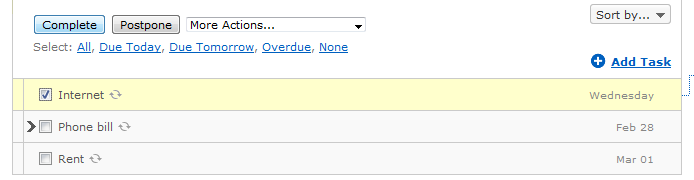
RTM then automatically adds a new task, due on the correct day of the next month, no matter what day I marked the current one as completed (paid).
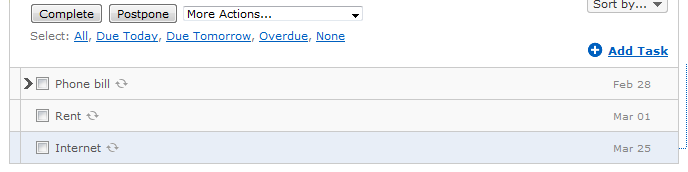
Since I am in the habit of checking my RTM lists for things I need to do anyway, I glance at the Bills list frequently so I know I am on top of what needs to be paid. Plus, it can be reassuring to check and see that the next bill due is a couple of weeks away. Remember The Milk was already useful for managing my other lists but once I got my bills list set up, it became indispensable.
Automated branching of subversion working copy
February 21, 2009 15:19
A question on Stack Overflow got me thinking that I would like to branch more often while using subversion but two things were preventing me:
- I wasn’t sure how to branch a working copy
- I never took the time to really learn about ‘svn switch’ so branching has always involved a time consuming checkout
So I decided to overcome these two obstacles and since I want to automate things, I decided to spend some time to write scripts to do the work for me. This way when I need to, I can branch and return to trunk with little effort.
I ended up with two scripts which I’ve put on GitHub, svn_wc2b (working copy to branch) and svn_b2wc (branch to working copy). They parse the svn info output to try to find the information needed without requiring me to type it every time.
If I want to branch a working copy I have of trunk, the svn_wc2b script will create a branch for my working copy and svn switch to it. There I can commit my work as needed until its complete. When work is done in the branch, the svn_b2wc script will svn switch back to trunk, merge the branch changes and delete the temporary working copy branch.
The main deficiency the scripts have right now is that they assume the working copy is in trunk and so branching from a branch is not yet supported. I will fix that when I get to a point where I need to do that. I’m hoping to incorporate more temporary branching into my normal processes at work when code isn’t quite ready for trunk, and to share in-progress code with other developers.
- My svn_scripts repository on GitHub
Optional behavior for Ruby heredocs
February 20, 2009 22:50
It’s right there in the documentation but since I haven’t seen all of these usages of Ruby heredocs much, I thought it was worth mentioning. The first example is standard, the other two are less common:
<<HEREDOC
This is like a double quoted string
Interpolation happens here. #{1+2}
Backslashes are interpreted as escapes. \a\t
HEREDOC
=> "This is like a double quoted string\nInterpolation happens here. 3\n
Backslashes are interpreted as escapes. \a\t\n"
<<'HEREDOC'
Interpolation doesn't happen here. #{1+2}
Backslashes are not interpreted as escapes. \a\t
HEREDOC
=> "Interpolation doesn't happen here. \#{1+2}\nBackslashes are not
interpreted as escapes. \\a\\t\n"
<<`HEREDOC`
uname -a
uptime
HEREDOC
=> "Linux kelethin 2.6.27-11-generic #1 SMP Thu Jan 29 19:24:39 UTC 2009
i686 GNU/Linux\n 21:50:27 up 2 days, 2:25, 5 users, load average: 0.20,
0.11, 0.03\n"Review your pending specs
February 20, 2009 21:29
I’m not a fan of pending specs or, more generally, tests which are present that aren’t being run. When I come across a pending spec, it raises questions but offers no answers.
- Why isn’t this test being run (not always clear from the reason given)
- Is this broken or missing functionality?
- Is this a broken test for working code?
- Was it to test functionality that has been removed?
Ideally we would all use pending specs sparingly, to remind ourselves of things which the application needs to do that we are going to work on soon. In practice with a team of developers this doesn’t always happen. Sometimes a developer doesn’t want to expend the effort to find why a test is failing. A bad idea, of course, but it happens. If you care about your tests you’ll want to know when it happens. Sometimes a (possibly empty) pending spec was written early by a developer thinking that it will probably be required, only to find out later that it wasn’t. Sometimes things like bugs in our tools or larger problems in our application prevent us from testing something we know should be tested so we mark the spec as pending.
When these pending specs are ignored, the uncertainty increases. People forget why something is pending. Everyone just gets used to see the messages go by and having those pending specs there just becomes normal.
I want as little uncertainty as possible. How do we fix the situation and prevent it from happening again? A good way is to make it obvious to team members when specs are marked pending. If everyone notices right away, perhaps someone knows a solution and it can be sorted out immediately instead of weeks or months later.
Initially, to keep a watch on our pending specs, my team at MDLogix started recording our number of pending specs during iteration retrospectives. By comparing our current number from the previous iteration’s we would know that at least we weren’t increasing the uncertainty. When we started tracking the numbers we had 51 specs marked as pending. This only accounted for about 1.5% of all our tests but every one of them could have been hiding something that was broken.
Our next step was to schedule time to actively review our pending specs to decide what action we should take on each one. Doing this was not an immediate need but we felt it would improve the quality of our code and tests. To make sure it got done we decided to create a regularly scheduled block of time for our “important but non-urgent” tasks. For two hours after lunch each Friday all team members work on the same task, which we identify in our stand-up meeting that morning.
We found that some pending specs were for functionality that had been removed when our code base had been extracted from an older larger application. Some actually hid problems that required fixing in our tests and code. Our plan is to reduce the number of pending specs in all the projects for which the team is responsible. Once this happens it will be apparent to all the team members when specs are made pending and we can all make sure the use is justified. We will make sure that any new pending specs will not be neglected!
Super Bowl ads less super in Canada
February 01, 2009 15:13
The press coverage leading up to a Super Bowl often focuses more on the big budget commercials more than the football game itself. Canadians always get the worst of this: they have to hear all the lead up stories about the ads which are going to be aired, and then they don’t get to see them during the Super Bowl!
We have the Canadian broadcasters, the Canadian Radio-television Telecommunications Commission (CRTC) and broadcast rights to thank for that. Canadian networks buy the rights to show US programs in Canada. That also buys them the right to override American network feeds in Canada. That means that even if a Canadian viewer makes sure to tune into NBC to watch the Super Bowl, they will be really watching the CTV (Canadian) feed, like it or not. With the Canadian feed being seen by much fewer people, the ads are much less expensive and similarly less impressive, often just normal commercials seen during any other show.
The CRTC calls this “signal substitution” and it apparently has confused enough people to make them create a Super Bowl-specific page to explain it. Signal substitution happens everyday, but it is not usually a big deal. When does someone actually know and care about what commercials are going to be seen during a particular show? Almost never, except for the Super Bowl.
Although I am in the US right now, I have Canadian satellite (Bell TV, formerly ExpressVu) for my television so I am in the same situation. For at least one previous Super Bowl, ExpressVu had worked some licensing magic to show the US broadcast with ads intact but I see no signs of that this year. I could drag out the rabbit ears and attempt to tune in the game but I think the hassle of finding and keeping a clear signal outweighs the small benefit of seeing the commercials. I’ll just watch them online tomorrow.
Money well spent
January 22, 2009 15:26
Clearly the future of digital advertising is to waste money on meaningless context-sensitive ads that go nowhere.

Just in case this was some clever advertising for some amazing new site on testing, I clicked the ad. It took me to this:
The site is now up again but unfortunately they don’t deal in the kind of testing I care about.
I think there was an error
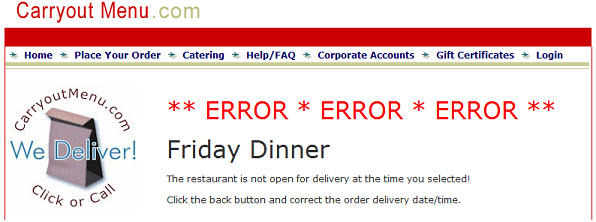
January 16, 2009 20:51
Really carryoutmenu.com? Three giant red errors? For something that any user might do while normally using your site?
Yes, I use Prolog and I like it
January 14, 2009 00:28
In the last couple of weeks I have been able to come back to doing some Prolog development at work after a very long break from it. I didn’t realize it before but my feelings toward writing Prolog code had been somewhat negatively affected by our troubles deploying Rails apps that call a particular Prolog interpreter. I had forgotten that I actually do really enjoy writing Prolog code. Here’s some quick thoughts on why I enjoy it and on a new project I’m starting where I hope to elaborate on these points.
Can be very fast
The code I have been maintaining lately is a scheduler. Although the data goes through a lot of processing before it reaches the Prolog code, the scheduler itself runs very fast. It can return a schedule for a consistent constraint network of hundreds of nodes in under a second.
Easy to gather data
A number of times the Rails side of our application required new information from the Prolog side. We have a clear, agreed upon API to call and return results between the two, and it was very easy to write new code to calculate and gather the extra information and make it part of our API for returning data.
Easily handles different cases
The system of backtracking used in Prolog lets the programmer describe any number of situations and what to do in each of them and the Prolog interpreter does the work of finding which apply to the current data.
Reliable
Of course it is possible to write buggy code in any language, but part of the good vibes I have for Prolog stem from the reliability of this particular work project. After the initial development the code was, and continues to be, very reliable (ignoring our deployment issues which weren’t related to the code itself). While the Ruby code calling Prolog changed and added features, only minor tweaks in the Prolog code were required for well over a year.
A modern Prolog site
From searches and blog monitoring, it is clear that Prolog gets little to no love, even in this time of open mindedness and people learning new and varied languages. I think part of that comes from the fact that Prolog’s main usage has not been in areas that a lot of people are interested in. I’ve written schedulers and theorem provers in Prolog, but not many small, useful apps or just something thrown together for fun.
To hopefully start discussions on this type of Prolog programming, and to highlight more accessible Prolog coding, I have started working on http://prologblog.com. The first posts I plan to make there will be about writing the site’s own blog application in Prolog itself.
A personal programming goal for 2009
January 01, 2009 01:35
I have started looking into Erlang recently. I have been intrigued enough that I am going to make learning Erlang and producing something useful with it my first personal programming goal of 2009.

To help me do so I am starting with the Programming Erlang book from Pragmatic Bookshelf and also the first three parts in their Erlang in Practice set of screencasts.
I find Erlang interesting because of some very obvious similarities to Prolog. This is not really surprising since Prolog is a part of Erlang’s history; the first implementation of Erlang was in Prolog. The fact that I use Prolog regularly has let me skim through some of the things that the Erlang tutorials and books seem to spend time saying “now I know this isn’t like other languages you use” but for a Prolog programmer, many of these things aren’t surprising anymore.
Another intriguing thing about Erlang is that which differentiates it from Prolog. For me that is the focus on networking and multiple processes. These are things which, while doable, were not common things to do in Prolog programming.
Since it is early going in this process I have more questions than answers at this point. I am curious what parts of Prolog I am not going to have in Erlang which I am going to really miss or maybe even having a hard time functioning without.
While I am sure the Erlang community is still small, as is the Prolog community, at least it will be more active right now (I hope!). I have a Google blog search on “prolog” and to call the rate of new posts a ‘trickle’ would be optimistic.
As I work on my goal I’ll write more about my Erlang experiences and how a Prolog programming perspective helps or hinders the learning process.