jeff.dallien.net
jeff @ dallien.net

Menu:

Post History:



Posts for March, 2009
Amalgamator
March 22, 2009 04:53
Now that I have determined for myself that writing a web app in Prolog is a reasonable thing to do, I am trying to decide what direction to take it in. What I’ve done so far is get a specific application written but I’d like to package up some code and come up with a pattern or set of conventions for designing and deploying Prolog web apps to make things easier for others.
Due to the fact that most of my experience with web apps is with Rails, I was tempted to just start organizing things the way a Rails application would be organized. I don’t want to just write a Rails clone, and I especially don’t want to do that just because its the thing I thought of first. To get some inspiration for possible structure, features and philosophy I could use in my code, I decided to explore what else is out there. My first stop is Sinatra.
![]()
The idea
For a long time I was idea starved when it came to new programming projects. The technical know-how was there, but what to build? Luckily these days I’ve got a list of ideas that I can’t keep up with. I picked something that would be useful to myself and that I could write fairly quickly.
I wanted to write an RSS feed joiner, something that would take two RSS feed URLs and merge them into a single feed, and most importantly, would remove duplicate articles from the newly created feed. The inspiration for this comes from the CBC’s Canadian news feed and Nova Scotia news feed. Both are interesting to me, but every day a few articles will show up in both feeds that are exactly the same. These are either some national issue that has local relevance or vice versa.
Amalgamator
A Friday evening and a Saturday later, the resulting Sinatra application is Amalgamator. You know it is free software because no marketing department would name it that. The code is on GitHub and a deployed instance is also available to use as part of this site. To parse the RSS feeds I used the Feedzirra gem for the first time and I found it simple to use and encountered no problems with it. I used RSpec for Test Driven Development and I deployed using Passenger.
Thoughts on Sinatra
I really enjoyed using Sinatra and it really felt suitable for this type of small application. Some of the things I could see that may influence my Prolog code are:
- The Sinatra style of declaring what routes the application responds to, and the code associated with each one. This really reminded me of the http_handler/3 predicate in the SWI-Prolog HTTP library. Consider the Hello World example for Sinatra:
require 'rubygems'
require 'sinatra'
get '/hi' do
"Hello World!"
endand a Hello World example for SWI-Prolog’s HTTP library:
:- http_handler('/hi', hello_world, []).
hello_world(_Request) :-
reply_html_page([], [p('Hello World!')]).- Layouts can be included at the end of source files. This matches the functionality of the templating system I’ve already extracted from Prolog Server Pages.
- Fewer files and less configuration to do than Rails.
One way I think I will ultimately differ from Sinatra is its lack of helpers for building HTML, such as links, image tags, and forms. I think I will want to add some of these to my code to make generating HTML easier in Prolog.
One of the reasons that Sinatra works as a minimal framework is the large number of Ruby libraries available as gems to do so many of the things a web (or any) application needs to do. Sinatra provides the basics and then the developer can bring in just what they need. This won’t work the same way in Prolog. There are Prolog libraries out there, but not to the extent they are being developed and released for Ruby.
Overall, I think having something similar to the style of a Sinatra application would be really good for those wanting to get an existing Prolog application on the web. I think my small detour to Sinatra was very beneficial. I gained some perspective on framework design and I also moved an idea off my todo list and into a useful application.
Serving static files without proxying
March 20, 2009 19:00
In preparation for working on the prologblog.com CSS, I wanted to change my Apache config to serve static files like CSS and JavaScript before those requests got passed to the Prolog application.
Adjusting the rewrite rules I was already using for a Rails application, I changed the Prolog Blog config to use this:
# Redirect all non-static requests to Prolog
RewriteCond %{DOCUMENT_ROOT}/%{REQUEST_FILENAME} !-f
RewriteRule ^/(.*)$ http://127.0.0.1:8000%{REQUEST_URI} [P,QSA,L]
and I was then able to remove my Proxy commands I used originally:
ProxyPass / http://127.0.0.1:8000/
ProxyPassReverse / http://127.0.0.1:8000/Does anyone know any reason why having the rewrite rule do all the proxying work wouldn’t be the best way? It has been working fine, but I was surprised by the fact that now no proxy commands are required.
Prolog Blog has an RSS feed
March 20, 2009 04:51
The chain continues, though I won’t be writing much about it tonight. I updated the front page of the Prolog Blog to use a page that is processed using the templating system I’ve extracted from Prolog Server Pages over the last couple of days.
The most important addition for today is an RSS feed for the Prolog Blog site. The templated files made it easier to implement, but I’m not terribly happy with the way I had to handle escaping the HTML tags within the RSS feed. My preferred method gave me a lot of trouble due to backtracking while looping through each post. I’ll probably revisit that in the next few days.
Templating system for Prolog
March 19, 2009 05:42
The latest work on my chain is to extract the templating system from the Prolog Server Pages project so that it could be used to process Prolog inside any file, not just an HTML file, and also so that it could be used without the session management and other Prolog Server Pages specific features.
I’ve added the extracted templating code to the Prolog Blog code on GitHub, though it could probably become its own project in the future which can then be used as part of any new versions of Prolog Server Pages.
Here is an example template:
greeting_noun(Noun) :-
Noun = 'world'.
/*<html>
<body>
<?, greeting_noun(X) ,?>
Hello <?= X ?>
</body>
</html>*/The file can contain both a section of normal Prolog code and a document to be processed, contained in comments (so that SWI-Prolog ignores it). Similar to ERB, there are special tags for embedding code, <? ?>, and for embedding code that will generate part of the page, <?= ?>.
As one would probably expect, the result of the processed file will be:
<html>
<body>
Hello world
</body>
</html>Prolog Server Pages
March 18, 2009 03:58
I mentioned to the wise Chris Strom this morning how I occasionally search Twitter for mentions of Prolog, and he suggested that I add a Twitter search for it to my Google Reader. Shortly after doing so, it turned up a conversation directly relevant to my ongoing chain.
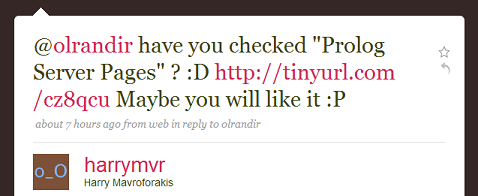
The linked page is an extensive discussion by Benjamin Johnston on the background and motivation behind Prolog Server Pages, a method of embedding Prolog code within an HTML page. This seems to be close to what I was hoping for on my wishlist the other day.
The implementation of Prolog Server Pages given seems to be a bit more than just a simple templating system but also provides session management as well. The predicates provided as part of the SWI libraries for generating HTML do have the advantage that they make it more difficult to produce invalid HTML. However, I am definitely going to use the templating portion as part of the Prolog Blog code. Not only will it save time in writing the pages the first time, I think it will make the pages in the site easier to understand and maintain. I have almost finished implementing an RSS feed as a templated file.
Having more Prolog code related to the web in any way is great too, as the ultimate goal of all this work is for me to learn new Prolog techniques and innovative uses of Prolog. I also realized that I need to continue searching for information about interfacing Prolog with the web, since I missed the work on Prolog Server Pages previously.
The pain of SQL Server
March 17, 2009 18:25
From the top of the README for the SWI-Prolog ODBC library, just above some Microsoft SQL Server-specific notes:
SWI-Prolog ODBC interface
I once thought Prolog was poorly standardised, but now I know better.
SQL is very poorly standardised.
The SWI-Prolog http_parameters library
March 17, 2009 02:43
Every incoming request to a server using the SWI-Prolog HTTP libraries has access to a request term, provided by http_handler/3, which contains the parameters from the request, along with all the other pieces of information one would expect the request to have (path, user agent, HTTP verb). The parameters are retrievable directly from the request, and could be parsed manually.
member(search(Params), Request).
I’m not entirely sure why the parameter term in the request list is called ‘search’. To save the work of parsing the parameters manually, the SWI http_parameters library includes predicates to do this, namely http_parameters/2 and http_parameters/3. The shorter of the two is just a convenience predicate that allows for omitting a list of options.
% include the http_parameters module
:- use_module(library('http/http_parameters')).
% calling:
http_parameters(Request, ParamsList).
% is the same as:
http_parameters(Request, ParamsList, []).
To retrieve the value of a parameter, pass the request term, and a list of terms with the parameter name and a variable. For example, if the parameter is called ‘page’:
http_parameters(Request, [page(Number, [])]).
In this example the Number variable will hold the value of the ‘page’ parameter. The empty list after the parameter is another list of options, this one is not optional. Omitting this list of options will result in a cryptic error message like the following:
Undefined procedure: http_parameters: (-)/2 In: [23] http_parameters: (-)/2 [22] http_parameters:fill_parameter/3 at /usr/lib/swi-prolog/library /http/http_parameters.pl:104
The types of options that can be included with each parameter include a default value, whether a parameter is optional (no error is thrown if an optional parameter is missing) and various conditions and type conversions. The full list of options is available in section 3.5 of the SWI-Prolog HTTP manual. Here is an example of a parameter named page with a default value. The Number variable will either be unified with the actual value of the page parameter or with the value 1 if the parameter is not present.
http_parameters(Request, [page(Number, [default(1)])]).prologblog.com is up and running
March 16, 2009 01:47
I’m not going to write much to add to the chain tonight, other than to say that prologblog.com is now up and running. The server code is on GitHub. As is the code that generates the first post. The site’s not pretty, and the list of things to do is a mile long, but the basic goal has been achieved, the site is running on a Prolog application.
I’ll go through the code and explain each part in subsequent posts, but here is a small introduction. This piece of code gathers all the post/1 predicates and flattens them into a single list. Using this method, new posts can been added to the system just by loading another source file with one or more post predicates into the interpreter. I’ll be using this method to add posts until I get some form of database access working.
all_posts(List) :-
setof(Post, post(Post), TempList),
flatten(TempList, List).
To make this work properly the main server source file has to declare that the post/1 predicates can be found in multiple files, using the multifile/1 predicate:
:- multifile post/1.Next up is adding some CSS to make the site look nicer, and working on a RSS feed. Feel free to try to break the Prolog Blog site with weird parameters and malformed requests, just be sure to let me know what happens.
Analysis paralysis
March 14, 2009 14:28
I’m expecting to write two chain posts today. The next post will have some actual code, this one has some thoughts on the direction the code will be going until I learn more.
As someone who has spent most of their time using a Prolog interpreter that is not SWI-Prolog, I am mindful of how it can be frustrating to find some interesting looking project only to find that it relies on an SWI library which doesn’t have an equivalent available for another interpreter. While I do believe in using the best tool for the job, I would also like to produce a solution that people can use with the interpreter with which they are already comfortable and in which they have existing code.
For the first time I can finally see why people write code using an SWI library and never look back. So far, the HTTP library has provided some solution to all the basic things I’ve needed and I think I’ll be able to focus on the overall application design much sooner than I expected because I figured I would be dealing with all kinds of lower level HTTP issues. At the moment I have no idea how many websites are running on Prolog but this library really makes the web pretty accessible to any existing Prolog programmer if they care to take the time to write the HTML generating parts.
I am going to stick with the SWI-Prolog libraries for now, but my long term goal is still to provide a web solution compatible with more than just SWI-Prolog. I don’t think I could design a good interface from the ground up without being familiar with what’s already done anyway. Recently I was talking to Terry Swift, a core developer for XSB and he mentioned that some Prolog implementations were looking to have better library compatibility with each other, so that may include the HTTP library I’ve been using.
Wishlist
- A way to use full HTML pages with some Prolog inside to add the dynamic parts, similar to how ERB is used in Rails. So far the page generating code has all been similar to Ruby’s Builder but with more punctuation, and it really feels like the entire page should not be generated by code. The Prosper framework may have had a solution for this, I will need to investigate.
Installing PlUnit on Ubuntu
March 14, 2009 05:46
Only a short update to the chain tonight because its getting late.
Before starting on the Prolog code for the prologblog.com site, I wanted to see if anyone in the Prolog community had documented how to do Test Driven Development (TDD) or Behavior Driven Development (BDD) in Prolog. I couldn’t even find some discussion on the subject let alone a how-to or tool set. For now, I will be on my own and figuring it out as I go.
The testing framework included with SWI-Prolog is called PlUnit. The Ubuntu SWI packages caused me to waste some more time today, as they don’t seem to include PlUnit, despite it being a package normally distributed with SWI. To use it, I had to get the current version directly from the SWI git respository. I kept the Ubuntu package-installed version of SWI and was able to manually install PlUnit next to it. Here are the steps for doing that.
Clone the SWI-Prolog git repository
git clone git://prolog.cs.vu.nl/home/pl/git/pl.git
Configure and install PlUnit
cd pl/packages/plunit autoconf ./configure sudo make install
Note that there is no actual ‘make’ step. There is nothing to build, the files just need to be copied into the correct location.
Check installation
To check that it was installed properly, one can run the files from the PlUnit examples directory.
cd pl/packages/plunit/examples/ # in the cloned git repo swipl -g "[simple],run_tests,halt." % simple compiled into ex_simple 0.01 sec, 108,664 bytes % PL-Unit: lists ........ done % All 8 tests passed
Apache reverse proxy to SWI-Prolog
March 13, 2009 03:34
It’s the second day of my chain, working towards having prologblog.com up and running a blog application written in Prolog itself. I spent some time tonight getting Apache to talk to directly to a demo app running on SWI-Prolog. While I consider myself capable around an Apache config, I still had to spend a good amount of time reading about proxy modules and options. It seemed that a simple “reverse proxy” is what I needed to start off with.
- With a forward proxy the client knows which destination URL it wants and has been specifically configured to use a proxy server to get it.
- With a reverse proxy, the client requests normal paths on the proxy server and a proxied result will be served to the client seamlessly. The client does not know that a proxy is involved, it all occurs on the server side.
Since the requests will be normal HTTP requests from anyone on the web, the reverse proxy is what I’m looking for. To setup the reverse proxy, I added the following lines to a virtual host configuration file:
ProxyRequests Off
<Proxy *>
Order deny, allow
Allow from all
</Proxy>
ProxyPass / http://127.0.0.1:8000/
ProxyPassReverse / http://127.0.0.1:8000/
The Prolog application, a simple Hello World program that responds to HTTP requests, was listening on port 8000, hence the ProxyPass address. It didn’t work immediately. I started off with a 500 error, and the following line in the error log:
[warn] proxy: No protocol handler was valid for the URL /. If you are using a DSO version of mod_proxy, make sure the proxy submodules are included in the configuration using LoadModule.
After some Googling, this was fixed by linking the proxy-http module file in /etc/apache2/mods-available to /etc/apache2/mods-enabled.
ln -s /etc/apache2/mods-available/proxy_http.load \
/etc/apache2/mods-enabled/proxy_http.load
I’m sure eventually I will have some more complex proxy setup for load balancing, serving static files, etc. but this config gets me by for now. My next steps for tomorrow will be putting a small Prolog application serving some simple content on the prologblog.com site, and reading about SWI-Prolog’s unit testing features, which I didn’t get around to tonight.
A chain of my own and making progress
March 12, 2009 03:31
Inspired by my colleague Chris Strom and his chain of self-improvement, I am starting one of my own. Chris described the chain this way:
The concept is that every day you produce something related to your craft. Each day you do this, you put an “X” through the day. After a little while, you have a chain of X’s and you begin to be offended at the idea of breaking the chain.
My chain will be getting prologblog.com up and running as a Prolog news, tutorial, and promotion site written in Prolog itself. After having this project on the back burner for a while I started working on it again just yesterday but without making much progress. The news is a bit better today.

Connect to Prolog using… Prolog
In general I want to keep my code for prologblog.com written in standard, portable Prolog which doesn’t depend on interpreter-specific libraries. That being said, it looks like SWI-Prolog has some pretty capable HTTP-related libraries that can act as the glue between my standard Prolog code and Apache.
There are many SWI-Prolog related packages in the Ubuntu repositories: the main interpreter itself, and then various libraries. Some of the packages might have missing dependencies because one can install the HTTP libraries without having the socket library installed, and the HTTP libraries failed to load without the socket library. This threw me off for a little while, since its not obvious which Ubuntu package includes the socket library (it’s swi-prolog-clib).
The command below will install SWI-Prolog and the socket and HTTP libraries. I then referred to the discussion and examples in the HTTP Support section of the SWI documentation.
sudo apt-get install swi-prolog swi-prolog-clib swi-prolog-http
For my next step, I am working on building the connecting layer using the HTTP library and investigating SWI’s unit testing support.
The simplest thing that could possibly fail miserably
March 11, 2009 03:39
When I’m at a B’more on Rails meeting, I might do more listening than talking but just attending gets me excited to work on things, especially when I hear what others are working on. So when I got home from tonight’s meeting I thought I would spend some time on one of the programming tasks on my todo list.
A couple of months ago while waiting for the January B’more on Rails meeting to start, I noticed that prologblog.com was available and I thought it would be not only a good learning experience but also beneficial to the Prolog community to have a site dedicated to practical Prolog programming. I could have had the site running long ago, except that my big idea was that I wanted to write the blog app itself in Prolog. The most Prolog code people are usually exposed to is some simple example of unification, like:
man(bob).
man(fred).
parent(fred, bob).
father(X,Y) :- parent(X,Y), man(X), man(Y).
son(X,Y) :- father(Y,X).
and so starting off with an actual application that isn’t too complicated but is at least useful, like a blog, seemed like a good idea.
I originally looked for an existing framework for Prolog web applications. The only thing I found was something called Prosper, which looked promising but has a dependency on a Windows-specific C library. I decided not to spend the time to port this code since I had no clue whether the Prosper framework was even going to be useful for me.
My next thought was to write some simple Prolog application myself, and connect it to the web server via Rack and Passenger. The hurdle to doing that was finding a Ruby interface to SWI-Prolog, in which I planned to write the application. When I couldn’t find an interface, the work to write that code became a bigger job than writing the Prolog code itself.
The paths to my goal which I thought to be the shortest were growing longer in front of me and were filled with a lot of boring work before I could get to the part that interested me. So, today I decided to tackle the problem with the mindset of using “the simplest thing which could possibly work.” The first thing that came to mind was to use perl, which I knew had some existing modules for connecting to SWI-Prolog and would of course would very easily handle requests from Apache and passing them on to Prolog.
I tried installing two different SWI perl modules and neither one would build the C code they needed properly. After installing some missing libraries I eventually ran into more compilation errors. I was now faced with my “simplest thing” being another long boring road to reach even a small amount of satisfaction.
The final result is that prologblog.com is no more live than it was when I wasn’t working on it. I’ve seen some threads on “using Prolog from PHP” where by “using” they really just mean a system call to the Prolog interpreter and inserting the output into the PHP page. I could use the same approach with any language ruby, perl, etc. but it feels clunky and it is definitely ugly. However, it is now my most likely “simplest thing that could possibly work,” which I may use just to get the project off the ground while I figure out something better.
Isolate sign-up spam with OtherInbox
March 08, 2009 12:28
So many sites require signup and email verification that sometimes I find myself leaving a site I would have liked to try because ![]() I hate having yet another account and potentially more spam email from each site and their advertisers. For those sites that I really do want to sign up for, I’ve been using OtherInbox for my sign-up email address and keeping the spam isolated. OtherInbox provides a web-based email account that is specifically designed to help organize email from many senders and keep it out of your primary email, thus acting as your “other inbox”.
I hate having yet another account and potentially more spam email from each site and their advertisers. For those sites that I really do want to sign up for, I’ve been using OtherInbox for my sign-up email address and keeping the spam isolated. OtherInbox provides a web-based email account that is specifically designed to help organize email from many senders and keep it out of your primary email, thus acting as your “other inbox”.
Here’s some of what makes OtherInbox great to use when creating accounts on new sites.
Invent new email addresses on the spot
An OtherInbox account gives you new email addresses without any setup. By default, any address can be created using the form sender @ username.otherinbox.com. For example, when I signed up for Technorati, I invented the address technorati@jdallien.otherinbox.com for my account. As soon as OtherInbox receives a message to a new email address, it will create a new mailbox for messages from that sender.
Verification link emails still come to you directly
Whenever OtherInbox receives an email from a sender it has not seen before, it forwards this first message to your primary email account. Since these emails often contain a “Click here to verify your account” link, no extra effort is required to verify these new accounts. After that first email comes to you, OtherInbox will keep any future messages and not tell you about each one.

Automatic message organization
OtherInbox has a nice interface for separating messages from each sender and indicates how many messages are unread from each sender as well. This happens automatically just by inventing a new email address and receiving an email at that address.
I have 1 OtherInbox beta invitation available so let me know in the comments (include an email address) if you’d like to give it a try.
The three faces of uploaded files in Rails
March 08, 2009 03:45
When using a file_field to upload files to a Rails app, the parameter containing the uploaded file can be one of three possible classes:
- If a user submits the form without selecting a file for the upload input field, the parameter will be an empty String.
- If the uploaded file is small, less than about 20 KB, the parameter will be an instance of ActionController::UploadedStringIO.
- If the file is larger, it will be saved as a temporary file and the parameter will be an instance of ActionController::UploadedTempfile.
It is possible to deal with objects of all three types without explicitly checking the class of the parameter. All three will respond to blank? but only the empty string (no file selected) will return true. Note that a zero length file will return false to blank?. Both types of file data have read and size methods and they do what one would expect.
One method to use with care is local_path. Although both uploaded data types respond to it, UploadedTempfile will return the path to the temporary file created on the server, and UploadedStringIO will return nil because no file was created in the filesystem. Some code that was incorrectly relying on a local_path being present caused the problem I encountered at work which made me aware of this issue.
Another way to deal with this is to let a plugin handle it. Plugins like attachment_fu deal with the different classes as part of their normal handling of uploaded files.
The solution for the particular piece of code we were dealing with was to change from attempting to explicitly open a temp file to using the blank? and read methods to get the uploaded data, regardless of type.
Using Google Effectively
March 03, 2009 22:37
It was suggested to me that I should share my thoughts on how I search effectively using Google. This turned out to be harder than I expected since I haven’t spent much time thinking about what I do, I’ve just been doing it. I will probably add more posts on this subject as I realize things I’ve omitted.
The key to finding things quickly with Google is to start with a half decent query and then refine it, possibly many times. Google provides some simple but important ways of searching and taking advantage of them all is important.
A good result rarely appears after the second page of results
If you don’t find what you are looking for early in the results, you need to refine your query. My first step for doing so is just adding another term. As a simple example, if I’m searching for something related to “Rails” and starting getting train references, sticking “Ruby” at the end of the query will usually solve that. As I look at result pages I try to find other terms which might be helpful in further narrowing down the results.
Try to imagine context
It can be difficult, but the better you can determine context from the two line page snippet that Google provides, the fewer irrelevant links you’ll need to click on. I scan the page titles first, then read the page snippets for the ones that sound relevant and click on the most promising one.
Put exact phrases in double quotes
Phrases in double quotes will be matched exactly, whereas an unquoted list of words will be matched anywhere in a page. This is especially useful for matching error messages exactly and eliminating pages which have partial matches but not exact ones.
Exclude things standing in your way
If you are seeing results about something unrelated to what you are searching for, clearing them out of the way might uncover what you really want. Do this by excluding search terms with a minus in front of them. Usually explicitly excluding one general, but irrelevant, term that you are seeing will remove many of those bad results and give you something new.
Let Google teach you
The Advanced Search page has a great feature that, like many things Google, stands out as being different. Like typical advanced search pages, it helps you build a query based on the different options available. The unique part is that it shows you the search query it is building at the top of the page, so that you can learn how to perform a similar search in the future from the Google main page, or your browser’s search box. Learning the various operators available to you is important as well.
Refine many times if necessary
I might change my search query five times or more while looking for something specific. I think that quickly evaluating the quality of what is returned and adjusting accordingly is my best strategy for tracking down exactly what I want.
I rarely give up on a search without finding something useful, so hopefully these suggestions will help others improve their searches. Please share any tips of your own in the comments!
Worst commit message ever
March 02, 2009 12:29